on
Blog Post 2
Economic trends in popular vote share of House elections
## Background
Today we will be exploring using economic models to attempt to predict popular vote share in United States House elections. The inspiration behind the models we will be looking at comes from the work of political scientists Achen and Bartels who looked into how voters vote retrospectively to either reward and punish leaders for economic performances from during their tenure. It also comes from the work of Healey and Lenz who looked at similar trends, specifically focused on how voters substitute the last year or even quarter of a term as a means to judge the entire tenure. In other words, the work of multiple political scientits has already shown that the economic sucess, particularly in the final months before an election, can help predict the results of an election. However, it is important to remember that most of this work was related to Presidential elections.
We will be attempting to take a deeper dive into using economic models to vote vote share in the House elections, which are obviously different from presidential elections. In all of my economic models, I choose to use Readl Disposable Income, or RDI. This simply represents the “extra money” that people have in their pocket books and in my estimations of how the average voter views the economy and their own economic gains, RDI is the best way to measure this. I almost immediately rejected the idea of simply looking at the change in RDI from the second to last to last quarter before an election. While this is the type of model which might have been used to predict the presidential elections from RDI, I saw low strength in this model and decided that if we were going to have an economic model with low accuracy and over-fitting problems, than I might as well take a deeper dive into testing more unique aspects of RDI.
The first aspect of RDI I choose to look at was the change into Quarter 5, which is the first Quarter of the election year (Example: The firt quarter of 2022). To look at the Quarter 5 change, I broke the data into two categories- one where the Quarter 8 changes (the Quarter immediately prior to the election) were negative and one were they were positive. Unfortunately, there happended to be a few enough Quarter 8s with negative gains that we will be primary be looking at when Quarter 8 has positive gains. While we don’t have this data yet for this election year, fortunately, it is very possible that the gains in RDI into Quarter 8 for 2022 will be positive because the economy (including RDI) has been down recently, particularly earlier this year, and it seems that RDI might improve as prices go down (particularly gas prices).
As you can see in the output below as well as the plot, this model predicts that in years where Quarter 8 has positive RDI change, as we increase the change in RDI in Quarter 5, we decrease the predicted vote share. While this does not make a lot sense upon first look, my first interpretation of this is that if voters had bigger gains earlier in the term, they may be looking for bigger gains later and if those gains are for whatever reason they may punish the incumbent party. Additionally, as Healy and Lenz discussed in their work, voters have short term memories. As a result of this, while they may remember big gains from the past, they may not attribute it to the incumbent party when it comes time to down. Finally, we should take note of the small R-Squared value and realize that this is also not a great model for predicting house vote share. R-Squared helps us interpret how much of the variance is explained by the independent variable. It goes from 0 to 1 and so R-Squared values, which I will be using throughout this blog, are what I am using to make judgments on how good models are.
##
## Call:
## lm(formula = H_incumbent_party_majorvote_pct ~ DSPIC_change_pct,
## data = data5)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.9779 -1.7691 -0.4867 2.4082 6.0269
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 52.3447 1.3414 39.02 <2e-16 ***
## DSPIC_change_pct -0.5632 1.0059 -0.56 0.58
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.333 on 27 degrees of freedom
## Multiple R-squared: 0.01148, Adjusted R-squared: -0.02513
## F-statistic: 0.3135 on 1 and 27 DF, p-value: 0.5801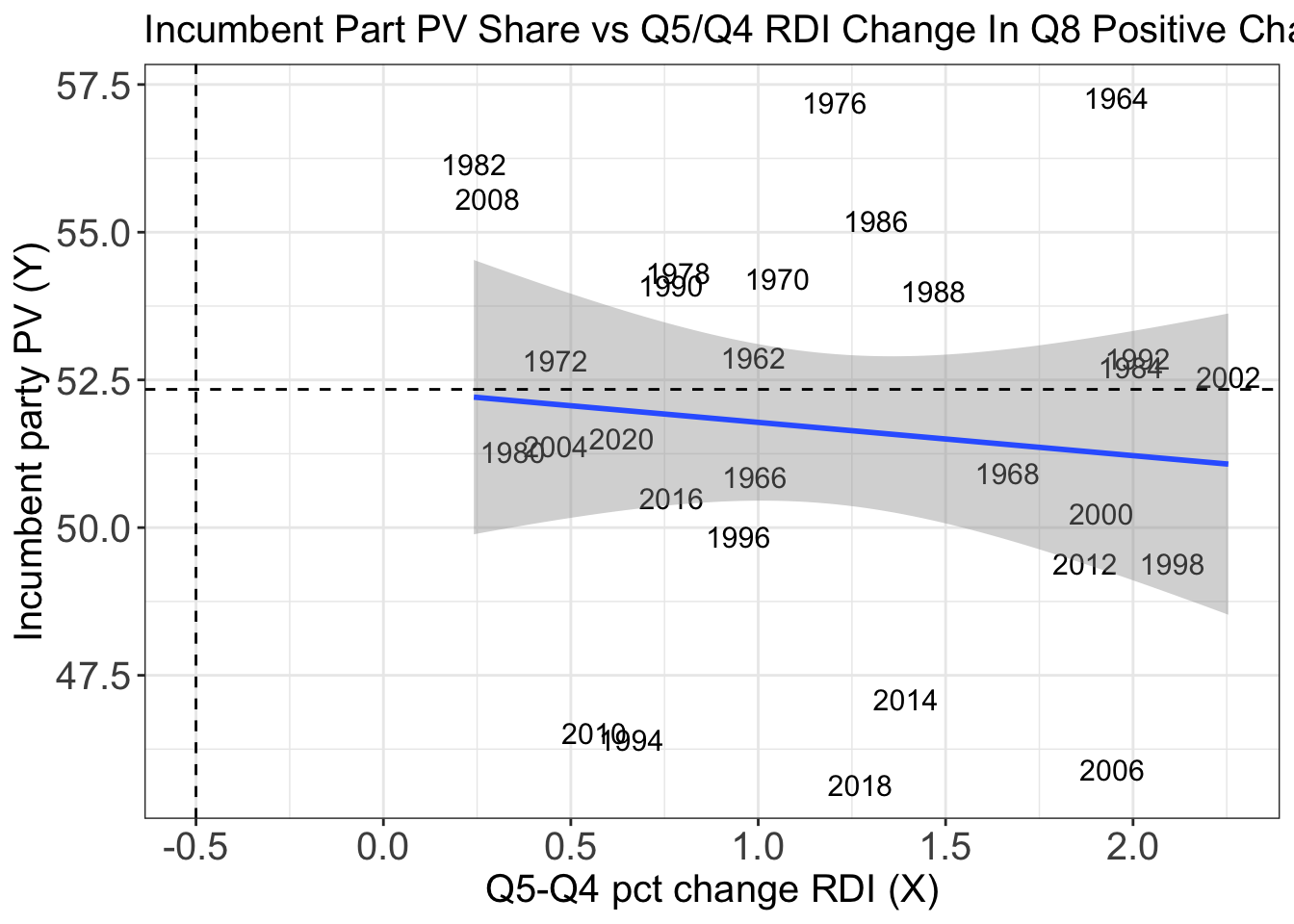
The next decision that I made was to return to looking at the Quarter 8 immediately before the election and adjusting that aspect of the model. To do this, I filtered the model to only include midterm election years. This created a definitely improved model, with an r-squared value of 0.47, meaning maybe we had found some real variation. The more interesting part of this finding, however, was that it showed that in midterm years, there was a significant decrease in popular vote share as the Quarter 8 RDI percent change increased.
##
## Call:
## lm(formula = H_incumbent_party_majorvote_pct ~ DSPIC_change_pct,
## data = data7)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.2002 -1.5572 -0.7778 2.5809 4.0432
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 53.917 1.121 48.118 4.93e-16 ***
## DSPIC_change_pct -4.502 1.319 -3.413 0.00462 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.185 on 13 degrees of freedom
## Multiple R-squared: 0.4726, Adjusted R-squared: 0.4321
## F-statistic: 11.65 on 1 and 13 DF, p-value: 0.004623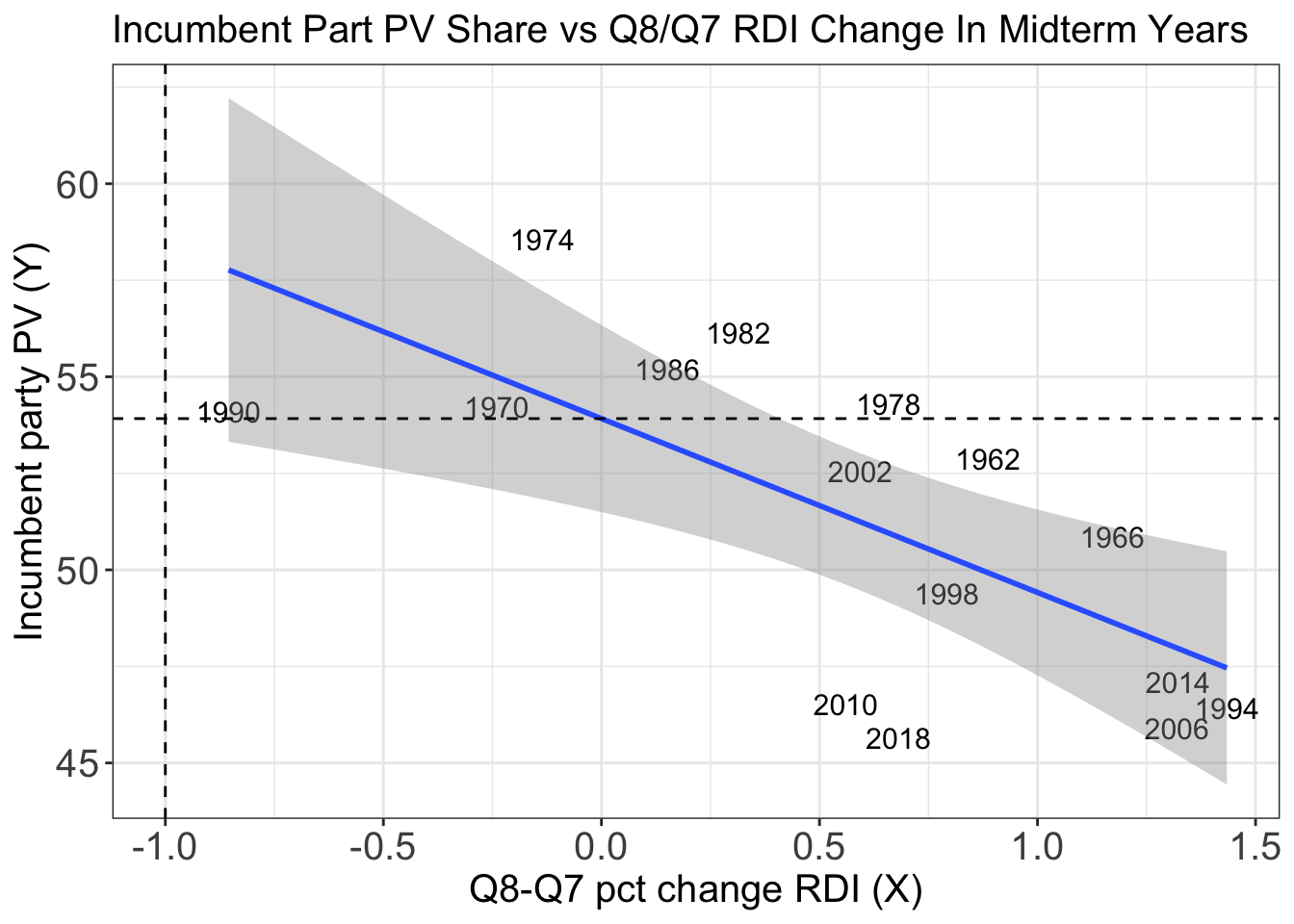
We should make note of the fact that this new model still isn’t perfect even with a slightly higher R-Squard. As can be seen in the plot below, while the incumbent party vote share has major variance, sometimes very high and sometimes low, the prediction sort of runs through the middle, and is sometimes right, but sometimes very positive or negative residuals which may just be averaging each other out.
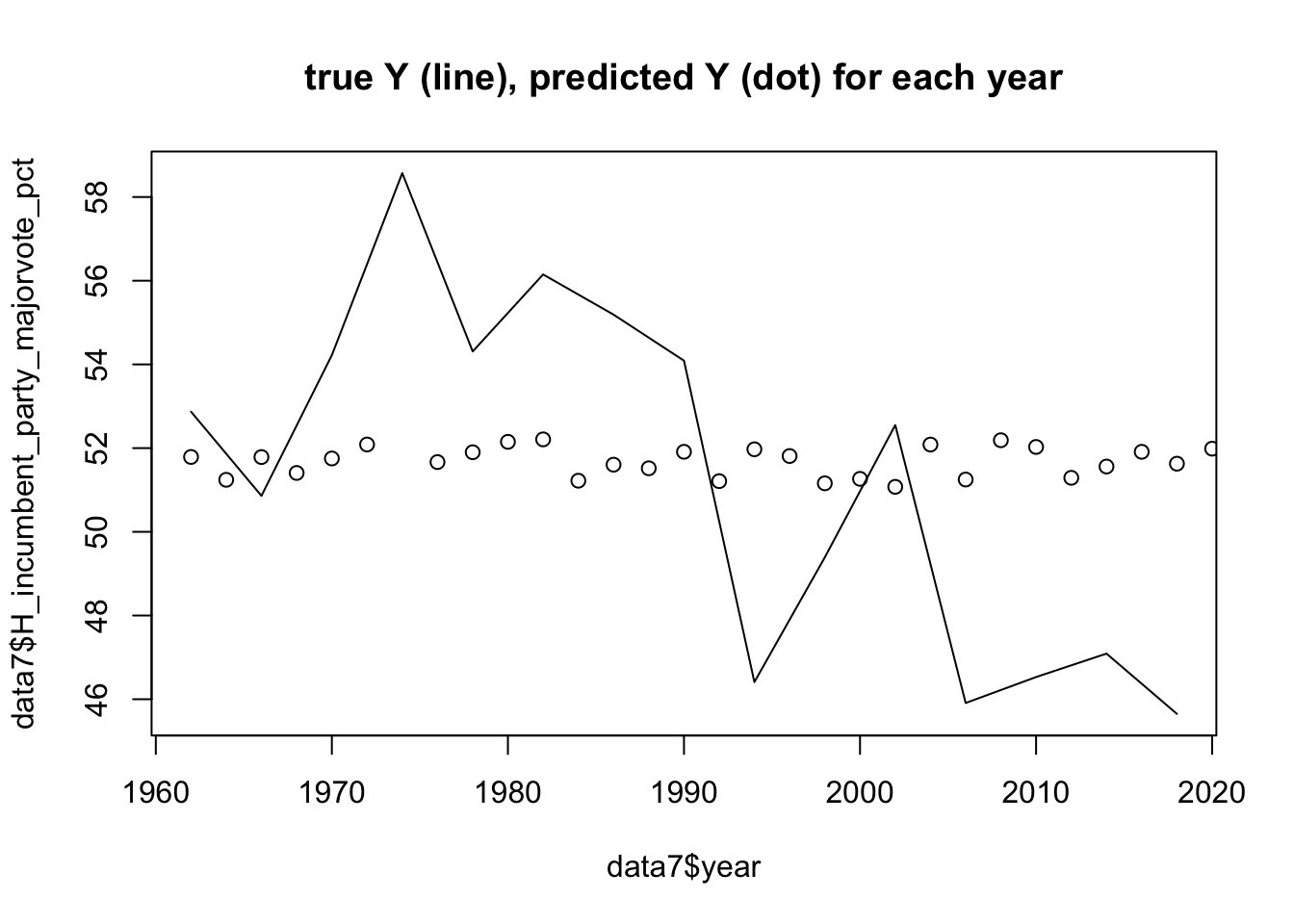
Ultimately, the conclusion from the work I have done in attempting all of the models I have tried is that there is unfortunately not an efficient way for us to accurately predict midterm/House election results. Through all of the models I tried to create, many not shown, I saw repeatedly very very low R-Squared numbers. For us to have a model where the in-sample data is that uncertain, we can not use it to make accurate conclusions. Fortunately, this finding is supported by the work of other political scientists who might agree that economic models alone don’t accurately predict elections. This on top of the fact that a lot of the existing models based on economic factors alone are usually for Presidential elections on top of all of the low predictivtity I saw in today’s models makes me comfortable with this conclusion.
Finally, we can use our model to make a prediction (with the caveat established above). The first model, which we established isn’t a great model, tells us that if Quarter 8 has a positive change in RDI, the Democrats should pick up around 53.48 percent of the popular vote share. Unfortunately, our model that was slightly more predictive, which involves using Quater 8 is of no use to us because Quarter 8 has not happened. Therefore, the prediction we were able to come up with should not be taken too accurately. As I established above, it is my beliefe that the economic models we attempted to build today only using economic variables versus vote share (like RDI, etc) are not highly predictive.
## 253
## 53.47295
Next, we can take a quick look at unemployment data. I was skeptical of having any success with this model because previous work of Wright which came to the conclusion that changes in unemployment do not necessarily predict elections. His findings were that unemployment was not a heuristic thing that impacted Presidential elections because it always benefited Democrats. That being said, as I expected, the brief work I did with unemployment again showed very little sensitivity in the model trying to predict House elections with unemployment data. In this case, even filtering for Democrats, in the second linear model seen below, there was a very very low R-Squared value in a model showing small increases in populare vote share with increass in unemployment prior to the election. The first linear model also predicts small increases for all incumbent parties as unemployment increases, also though a bad model with low R-Squared. Just as I had predicted, unemployment, especially for house elections, is not a good way to predict future elections.
##
## Call:
## lm(formula = H_incumbent_party_majorvote_pct ~ Unemployed_prct,
## data = unemploymentState4)
##
## Residuals:
## Min 1Q Median 3Q Max
## -8.069 -2.296 0.216 2.684 7.122
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 48.6874 0.2760 176.40 <2e-16 ***
## Unemployed_prct 0.4315 0.0431 10.01 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.224 on 1217 degrees of freedom
## Multiple R-squared: 0.07611, Adjusted R-squared: 0.07535
## F-statistic: 100.3 on 1 and 1217 DF, p-value: < 2.2e-16##
## Call:
## lm(formula = H_incumbent_party_majorvote_pct ~ Unemployed_prct,
## data = unemploymentState5)
##
## Residuals:
## Min 1Q Median 3Q Max
## -7.1448 -2.2883 0.6728 2.6219 5.5704
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 50.99326 0.37806 134.880 < 2e-16 ***
## Unemployed_prct 0.19573 0.05435 3.602 0.000336 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.379 on 793 degrees of freedom
## Multiple R-squared: 0.01609, Adjusted R-squared: 0.01485
## F-statistic: 12.97 on 1 and 793 DF, p-value: 0.000336